Search and Access data
HDA service allows to search and access DEDL data. We show how to do it sending a few HTTP requests to the API, using Python code.
Setup
We start off by importing the relevant modules for HTTP requests and json handling.
from typing import Union
import requests
import json
import urllib.parse
from IPython.display import JSON
from IPython.display import Image
import geopandas
import folium
import folium.plugins
from branca.element import Figure
import shapely.geometry
And defining the relevant constants, holding the URL strings for the different endpoints.
# IDS
COLLECTION_ID = "EO.EUM.DAT.SENTINEL-3.SL_1_RBT___"
ITEM_ID = "S3B_SL_1_RBT____20240918T102643_20240918T102943_20240919T103839_0179_097_336_2160_PS2_O_NT_004"
# Core API
HDA_API_URL = "https://hda.data.destination-earth.eu"
# STAC API
## Core
STAC_API_URL = f"{HDA_API_URL}/stac"
## Item Search
SEARCH_URL = f"{STAC_API_URL}/search"
## Collections
COLLECTIONS_URL = f"{STAC_API_URL}/collections"
COLLECTION_BY_ID_URL = f"{COLLECTIONS_URL}/{COLLECTION_ID}"
## Items
COLLECTION_ITEMS_URL = f"{COLLECTIONS_URL}/{COLLECTION_ID}/items"
COLLECTION_ITEM_BY_ID_URL = f"{COLLECTIONS_URL}/{COLLECTION_ID}/items/{ITEM_ID}"
Authenticate
To search and access DEDL data we need to have a DestinE user account. We can then authenticate and be able to search and access DEDL data. The authentication will provide the user with an access token to be used for searching and accessing data.
import json
import os
from getpass import getpass
import destinelab as deauth
DESP_USERNAME = input("Please input your DESP username or email: ")
DESP_PASSWORD = getpass("Please input your DESP password: ")
auth = deauth.AuthHandler(DESP_USERNAME, DESP_PASSWORD)
access_token = auth.get_token()
if access_token is not None:
print("DEDL/DESP Access Token Obtained Successfully")
else:
print("Failed to Obtain DEDL/DESP Access Token")
auth_headers = {"Authorization": f"Bearer {access_token}"}
Search data
Using the obtained access token, the user can search for data belonging to the collections of interest.
Search items in a collection
There are different ways to search data in a specific collection, in this example we are going to search into the SLSTR Level 1B Radiances and Brightness Temperatures - Sentinel-3 dataset (collection ID: EO.EUM.DAT.SENTINEL-3.SL_1_RBT___).
The easiest way for searching data is to get the list of items available in a given Collection using a simple search and sorting the results. The default number of returned results is 20, but it is possible to specify the number of item returned with the limit parmeter. It is also possible paginate the results.
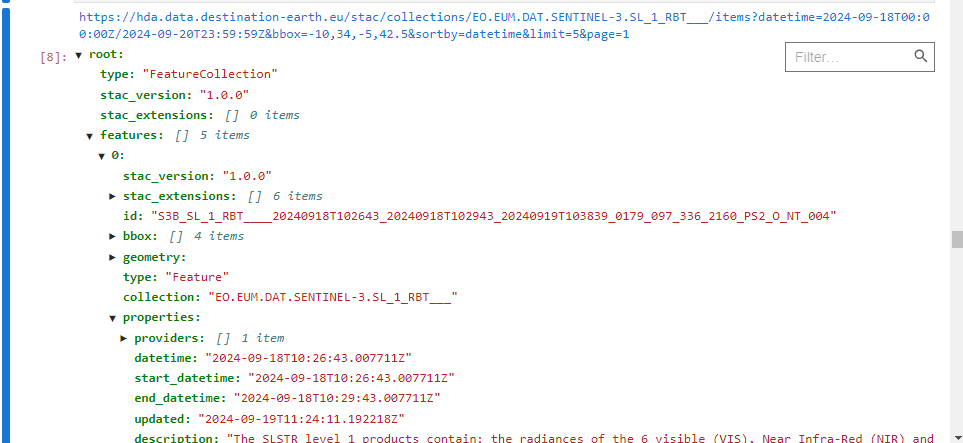
FILTER = "?datetime=2024-09-18T00:00:00Z/2024-09-20T23:59:59Z&bbox=-10,34,-5,42.5&sortby=datetime&limit=5&page=1"
print(COLLECTION_ITEMS_URL+FILTER)
response=requests.get(COLLECTION_ITEMS_URL+FILTER, headers=auth_headers)
JSON(response.json())
The most complete way to search data is using the stac/search endpoint.
The STAC API provides stac/search endpoint that allows users to efficiently search for items that match the specified input filters. By default, the /stac/search endpoint will return the first 20 items found in all the collections available at the /stac/collections endpoint.
Filters can be added either via query parameters in a GET request or added to the JSON body of a POST request.
GET request, the query parameters are added at the end of the URL as a query string: ?param1=val1¶m2=val2¶m3=val3
FILTER = "&datetime=2024-09-18T00:00:00Z/2024-09-20T23:59:59Z&bbox=-10,34,-5,42.5&sortby=datetime&limit=10"
SEARCH_QUERY_STRING = "?collections="+COLLECTION_ID+FILTER
response=requests.get(SEARCH_URL + SEARCH_QUERY_STRING, headers=auth_headers)
JSON(response.json())
POST request, the query parameters are added to the JSON body of the request
BODY = {
"collections": [
COLLECTION_ID,
],
"datetime" : "2024-09-18T00:00:00Z/2024-09-20T23:59:59Z",
"bbox": [-10,34,
-5,42.5 ],
"sortby": [{"field": "datetime","direction": "desc"}
],
"limit": 10,
}
response=requests.post(SEARCH_URL, json=BODY, headers=auth_headers)
JSON(response.json())
Note
The available query parameters for each collection depend on the specific data provider. The most common query parameters are datetime and bbox.
The available providers, and related roles, for a given collection are listed in its metadata.
The available query parameters for a specific collection/provider can be obtained using the STAC API - Filter Extension
Multiple data provider sources can be referenced for a given collection, to perform the search on a specific data provider please add the filter provider to your query.
Access data
The items belonging to a specific collection can be downloaded entirely, or it is possible to download a single asset of a chosen item.
The URLs to download the entire item or the single assets can be found in the metadata of the chosen item (identified by its itemID in a collection). The user can request the /stac/collections/{collectionID}/items/{itemID} endpoint to discover those URLs inside the assets metadata.
print(COLLECTION_ITEM_BY_ID_URL) response=requests.get(COLLECTION_ITEM_BY_ID_URL, headers=auth_headers) JSON(response.json())

Download an item
To download the entire item we need to use the URL contained in the downloadLink asset
result = json.loads(response.text)
downloadUrl = result['assets']['downloadLink']['href']
print(downloadUrl)
resp_dl = requests.get(downloadUrl,stream=True,headers=auth_headers)
# If the request was successful, download the file
if (resp_dl.status_code == HTTP_SUCCESS_CODE):
print("Downloading "+ ITEM_ID + "...")
filename = ITEM_ID + ".zip"
with open(filename, 'wb') as f:
for chunk in resp_dl.iter_content(chunk_size=1024):
if chunk:
f.write(chunk)
f.flush()
print("The dataset has been downloaded to: {}".format(filename))
else: print("Request Unsuccessful! Error-Code: {}".format(response.status_code))
Note
For some data providers (e.g. Copernicus Climate data sore and Copernicus atmosphere data store) the URL in the downloadLink asset will redirect to another URL to check the status of the download job and get the proper download URL when it is ready. A code example for this kind of download can be found at Request a subset of data.
Download a single asset of an item
The metadata of a given item contains also the single assets download link, that the user can use to download a specific asset of the chosen item. In the example below we download the asset: “xfdumanifest.xml”
downloadUrl = result['assets']['xfdumanifest.xml']['href']
print(downloadUrl)
resp_dl = requests.get(downloadUrl,stream=True,headers=auth_headers)
# If the request was successful, download the file
if (resp_dl.status_code == HTTP_SUCCESS_CODE):
print("Downloading "+ result['assets']['xfdumanifest.xml']['title'] + "...")
filename = result['assets']['xfdumanifest.xml']['title']
with open(filename, 'wb') as f:
for chunk in resp_dl.iter_content(chunk_size=1024):
if chunk:
f.write(chunk)
f.flush()
print("The dataset has been downloaded to: {}".format(filename))
else: print("Request Unsuccessful! Error-Code: {}".format(response.status_code))
Visualize the quicklook
Image(url=result['assets']['thumbnail']['href'], width=500)

The notebook to search and access DEDL data is available here: HDA tutorial