Request a subset of data
Some collections, e.g. the Copernicus services collections produced by ECMWF and the DestinE digital twins outputs, offer a wide range of data, information, variables and constraints. We often need only a portion of the data available, we can then request only a subset of data.
The data inside this kind of collections can be filtered in order to request only the desired portion of data. This can be done using a list of variable terms specific for each collection.
These variable terms can be recovered using the queryable endpoint as explained in Filtering and queryables API
Below an example on how to do it sending a few HTTP requests to the API, using Python code.
Setup
We start off by importing the relevant modules for HTTP requests and json handling.
import requests
import json
import os
from getpass import getpass
import destinelab as deauth
from IPython.display import JSON
Authenticate
To search and access DEDL data we need to have a DestinE user account. We can then authenticate and be able to search and access DEDL data. The authentication will provide the user with an access token to be used for searching and accessing data.
import json
import os
from getpass import getpass
import destinelab as deauth
DESP_USERNAME = input("Please input your DESP username or email: ")
DESP_PASSWORD = getpass("Please input your DESP password: ")
auth = deauth.AuthHandler(DESP_USERNAME, DESP_PASSWORD)
access_token = auth.get_token()
if access_token is not None:
print("DEDL/DESP Access Token Obtained Successfully")
else:
print("Failed to Obtain DEDL/DESP Access Token")
auth_headers = {"Authorization": f"Bearer {access_token}"}
Filtering to get a subset of data
Using the obtained access token, the user can filter the proper collections to get a subset of data.
The ‘ERA5 hourly data on single levels from 1940 to present’ is used here to demonstrate this feature. We are going to ask for a certain variable, 2m_temperature, at a certain hour in a specific date.
datechoice = "2020-06-10T10:00:00Z"
filters = {
key: {"eq": value}
for key, value in {
"format": "grib",
"variable": "2m_temperature",
"time": "12:00"
}.items()
}
response = requests.post("https://hda.data.destination-earth.eu/stac/search", headers=auth_headers, json={
"collections": ["EO.ECMWF.DAT.REANALYSIS_ERA5_SINGLE_LEVELS"],
"datetime": datechoice,
"query": filters
})
product = response.json()["features"][0]
JSON(product)
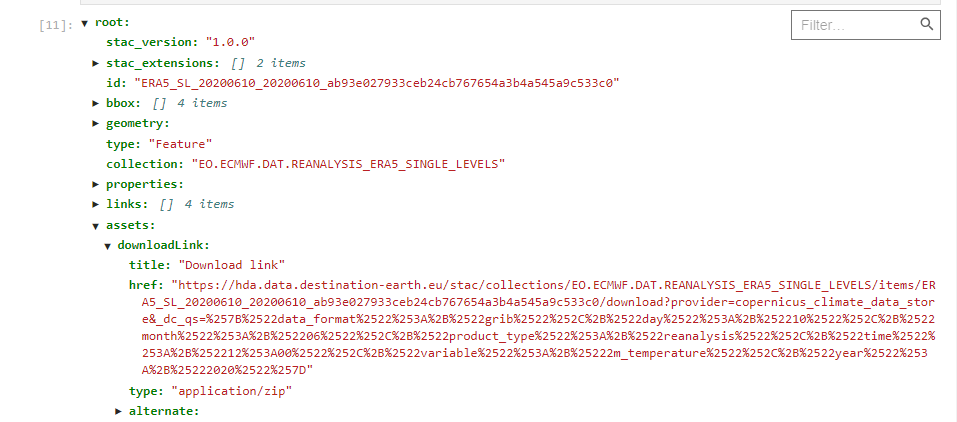
Access the requested subset of data
Requests for the collections produced by ECMWF and DestinE digital twins collections always return a single item containing all the requested data. The asset DownloadLink represents then the requested subset of data and can be used to download what requested.
If the data subset has already been requested, it is possible to download it directly using the DownloadLink URL, otherwise it is needed to check the status of the download request and wait until it is processed. Below the code that manages both situations, data already chached and data to be processed to be downloaded.
If the data is already available in the cache we can directly download it. If the data is not available, we can see that our request is in queued status. We will then poll the API until the data is ready and then download it.
download_url = product["assets"]["downloadLink"]["href"]
print(download_url)
HTTP_SUCCESS_CODE = 200
HTTP_ACCEPTED_CODE = 202
direct_download_url=''
response = requests.get(download_url, headers=auth_headers)
if (response.status_code == HTTP_SUCCESS_CODE):
direct_download_url = product['assets']['downloadLink']['href']
elif (response.status_code != HTTP_ACCEPTED_CODE):
print(response.text)
response.raise_for_status()
from tqdm import tqdm
import time
import re
# we poll as long as the data is not ready
if direct_download_url=='':
while url := response.headers.get("Location"):
print(f"order status: {response.json()['status']}")
response = requests.get(url, headers=auth_headers, stream=True)
response.raise_for_status()
filename = re.findall('filename=\"?(.+)\"?', response.headers["Content-Disposition"])[0]
total_size = int(response.headers.get("content-length", 0))
print(f"downloading {filename}")
with tqdm(total=total_size, unit="B", unit_scale=True) as progress_bar:
with open(filename, 'wb') as f:
for data in response.iter_content(1024):
progress_bar.update(len(data))
f.write(data)
The notebook to search, access and visualize the ‘ERA5 hourly data on single levels from 1940 to present’ is available here: CDS data access with HDA