Using s3cmd to obtain Fresh Data Pool (EODATA) on Destination Earth
In this article, you will learn how to access Fresh Data Pool (EODATA) on Destination Earth Data Lake, using s3cmd, a command-line tool for managing S3 storage.
DEDL Fresh Data Pool includes satellite imagery and environmental data. The former is also known as Fresh Data Pool (EODATA) (Earth Observation Data) and s3cmd allows you to access and manage these large datasets stored in AWS S3 format using command-line operations.
What we are going to cover
Fresh Data Pool (EODATA) Storage Endpoint
S3 is an object storage service that allows you to retrieve data over HTTPS using a REST API. The default S3 endpoint address to work with Fresh Data Pool(EODATA) on Destination Earth is:
https://eodata.data.destination-earth.eu
Prerequisites
Access to My DataLake Services
You need access to My DataLake Services. See article How to create a profile on My DataLake Services.
Credentials for S3 EODATA access from My DataLake Services
See the article How to obtain EODATA S3 keys through My DataLake Services
s3cmd installed on your local computer or virtual machine
S3cmd is a free and open-source tool used for managing S3-compatible cloud storage systems, like Fresh Data Pool (EODATA). In this article, you will use it to interact with your resources hosted on Destination Earth cloud.
This article was written for Ubuntu 22.04. The commands may work on other operating systems but might require adjustment.
To install s3cmd on Ubuntu 22.04, run:
sudo apt install s3cmd
Configuring s3cmd for Fresh Data Pool (EODATA) acess
Before you can start using s3cmd to interact with the Fresh Data Pool (EODATA) repository, you need to configure it with your credentials. Run the following command to configure the tool:
s3cmd --configure
You will be prompted to enter the following details:
Access Key: YOUR_ACCESS_KEY
Secret Key: YOUR_SECRET_KEY
S3 Endpoint: eodata.data.destination-earth.eu
Use HTTPS protocol [Yes]: Yes
DNS-style bucket+hostname:port template: s3://%(bucket)s.%(location)s
Encryption password: (Leave empty if no encryption is used)
Once configured, s3cmd will store your credentials in ~/.s3cfg, allowing you to use it for future interactions.
For additional information on s3cmd config files, see Configuration files for s3cmd command.
Browsing Fresh Data Pool (EODATA) with s3cmd
You can browse the Fresh Data Pool (EODATA) repository using s3cmd, which is a convenient tool for quickly checking the contents of your cloud storage. To explore directories, use the following s3cmd command:
s3cmd ls s3://EODATA/ --host=https://eodata.data.destination-earth.eu
This command lists the available datasets in the root directory of the Fresh Data Pool (EODATA) bucket.
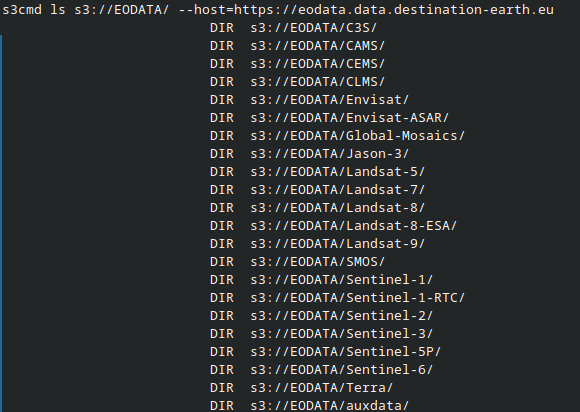
You can then navigate deeper into subdirectories by appending the appropriate path, as shown in the next section.
Listing Files with s3cmd ls
To list the contents of a specific directory, use the s3cmd ls command. Below is an example that lists the contents of a specific directory:
s3cmd ls s3://EODATA/Envisat-ASAR/ASAR/ASA_WSS_1P/2012/04/08/ \
--host=https://eodata.data.destination-earth.eu
This command will display a list of subdirectories or files:
2022-10-10 09:30 PRE ASA_WSS_1PNESA20120408_110329_000000603113_00267_52867_0000.N1/
2022-10-10 09:32 PRE ASA_WSS_1PNESA20120408_110428_000000603113_00267_52867_0000.N1/
2022-10-10 09:35 PRE ASA_WSS_1PNESA20120408_110446_000000603113_00267_52867_0000.N1/
Path format guidelines
When using s3cmd ls, make sure to follow these rules when specifying paths:
Use / as a separator between directories.
Do not start the path with a leading slash.
Always end the path with a slash to list the contents of a folder.
The first part of the path must be a dataset available at the root level (e.g., Sentinel-1, Sentinel-2, Envisat-ASAR).
Optional: Filtering Output in Bash
You can filter the directory names from the listing output using a combination of s3cmd ls and awk. This will display only the directory names:
s3cmd ls s3://EODATA/Envisat-ASAR/ASAR/ASA_WSS_1P/2012/04/08/ \
--host=https://eodata.data.destination-earth.eu \
| awk '{print $4}'
This command will return:
ASA_WSS_1PNESA20120408_110329_000000603113_00267_52867_0000.N1/
ASA_WSS_1PNESA20120408_110428_000000603113_00267_52867_0000.N1/
ASA_WSS_1PNESA20120408_110446_000000603113_00267_52867_0000.N1/
Downloading PNG files from Fresh Data Pool (EODATA) repository
Basic Info on PNG Files
PNG stands for Portable Network Graphics, a raster image format known for:
Storing pixel-based image data,
Supporting transparency,
Providing lossless compression.
In Earth Observation (EO) data, .png files are often used to represent processed imagery, such as false-color composites or classification maps. These files are typically not geo-referenced like .tif or .SAFE files but offer quick, visual access to EO content.
How to download a PNG file with s3cmd
To download a .PNG file using s3cmd, use the following command:
s3cmd get s3://EODATA/Landsat-5/TM/L1T/2011/11/16/LS05_RMPS_TM__GTC_1P_20111116T100042_20111116T100111_147386_0194_0035_4BF1/LS05_RMPS_TM__GTC_1P_20111116T100042_20111116T100111_147386_0194_0035_4BF1.BP.PNG \
--host=https://eodata.data.destination-earth.eu
This command will download the file to your current working directory. If the file already exists locally, it will be overwritten without prompting for confirmation.
After running the command, you will see the download progress. Once completed, the file will be available in your current directory.
Expected Output
Here is an example of a downloaded PNG visualization from Fresh Data Pool:
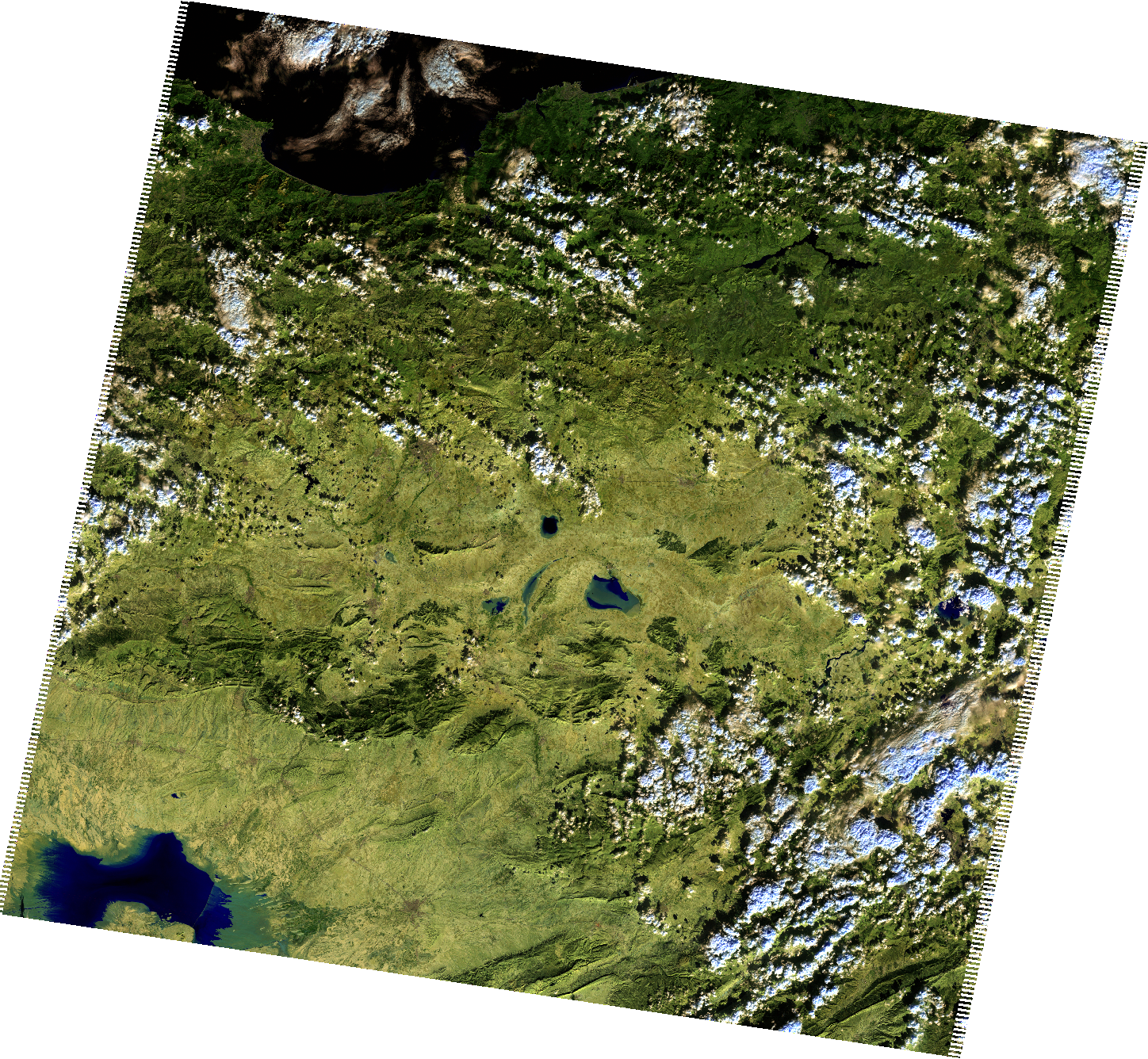
Example of a downloaded PNG visualization from Fresh Data Pool
Downloading .EOF Files from Fresh Data Pool (EODATA) Repository
What is a .EOF File?
EOF stands for Earth Observation Format, a custom format used to store and share EODATA, often containing both image data and metadata. These files are used in environmental and Earth sciences, including research and commercial EODATA systems. Typically, .EOF files require specialized software to read and process.
Downloading .EOF File with s3cmd
To download a .EOF file using s3cmd, use the following command:
s3cmd get s3://eodata/Sentinel-1/AUX/AUX_POEORB/2023/10/03/S1A_OPER_AUX_POEORB_OPOD_20231024T080719_V20231003T225942_20231005T005942.EOF \
--host=https://eodata.data.destination-earth.eu \
/your/path/to/python_eodata/
Replace the path with your desired location before running the command.
Downloading .TIFF Files from Fresh Data Pool (EODATA) Repository
What is a .TIFF File?
TIFF stands for Tagged Image File Format, commonly used in Earth Observation for storing satellite images. TIFF files can store geospatial metadata along with large raster images, making them ideal for EODATA that requires high precision. TIFF files can include information such as:
Satellite position,
Acquisition time,
Image resolution.
This format is widely used due to its flexibility, as it can support various types of data, including multi-band and multi-page data sets.
How to download a .TIFF file with s3cmd
To download a .TIFF file using s3cmd, use the following command:
s3cmd get s3://eodata/Sentinel-1/SAR/SLC/2019/10/13/S1B_IW_SLC__1SDV_20191013T155948_20191013T160015_018459_022C6B_13A2.SAFE/measurement/s1b-iw1-slc-vh-20191013t155949-20191013t160014-018459-022c6b-001.tiff \
--host=https://eodata.data.destination-earth.eu \
/your/path/to/download/
The command will download the .TIFF file to your specified local directory. Replace /your/path/to/download/ with the path where you want the file saved.
Expected Output
Once downloaded, the .TIFF file will be available in the directory specified.
Downloading .SAFE files from Fresh Data Pool (EODATA) repository
What is a .SAFE File?
The .SAFE format is a directory-based structure used primarily by the European Space Agency (ESA) for Sentinel satellite missions. It is not a single file but a directory that includes metadata, image bands, calibration data, and other auxiliary files necessary for processing the satellite data.
The .SAFE file format is specifically designed for use with Sentinel-1, Sentinel-2, and other ESA mission data. These files can include multiple geospatial datasets that are essential for advanced analysis. This directory structure includes several components such as:
- Granules
The satellite data collection units that typically include imagery and other related files.
- Metadata
Includes both product-level and granule-level metadata describing the image or data.
- Bands
The individual layers of imagery collected by the satellite sensor.
The .SAFE file format is required to interpret data properly in an Earth Observation context. Files and subdirectories in .SAFE format include various image formats like .tiff for imagery and .xml for metadata.
How to Download .SAFE Files with s3cmd
To download an entire .SAFE directory recursively, use the following command:
s3cmd get --recursive s3://eodata/Sentinel-1/SAR/SLC/2019/10/13/S1B_IW_SLC__1SDV_20191013T155948_20191013T160015_018459_022C6B_13A2.SAFE/ \
--host=https://eodata.data.destination-earth.eu \
/your/path/to/download/
This command will recursively download all files within the .SAFE directory to your specified local directory.
Files downloaded from this .SAFE project
Here are the directories downloaded for this .SAFE project:
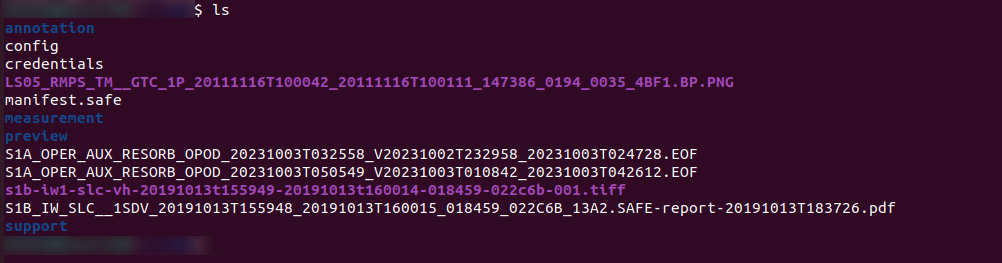
File /preview/quick-look.png shows what part of Earth surface has been observed and recorded in .SAFE format:

Under the measurement subdirectory, we see the downloaded .TIFF files:

Note that .TIFF files are all longer than 1 GB of data.
There is also a PDF file for the .SAFE product:

Expected Output
The .SAFE directory, along with all its contents, will be downloaded to the directory you specify. Once downloaded, you can proceed with processing the imagery and metadata contained within.
Eventual problems when downloading .SAFE files
.SAFE format consists of a large number of files, and the main problem is that they can become corrupted during the download. Other issues include incomplete downloads, slow speeds, or API throttling.
To mitigate these issues, ensure you have a stable internet connection and enough storage space. Additionally, the AWS S3 service limits the number of objects per request (1000), so large directories may require multiple requests.
Other common problems include:
Firewall or network configuration issues
Timeouts
Invalid or missing metadata
Unrecognized or unsupported file formats
Nested directory structure handling
What To Do Next
To access Fresh Data Pool (EODATA) on Destination Earth, you can also use boto3 Python library and AWS CLI:
Using AWS CLI to access Fresh Data Pool (EODATA) on Destination Earth
Using boto3 to access Fresh Data Pool (EODATA) on Destination Earth